
take my wor(l)d
how we will tell stories together.

The writer Ursula K. Le Guin would begin each new novel by first drawing a map. The represented world was the origin of the story. Today, AI can generate a navigable world from a single image. Le Guin's maps were mental models made visible; now, we have quite literal world models that can simulate the physics and logic of imagined spaces. We enter images and watch worlds unfold.
Videos and images used to be artifacts of unrepeatable experiences. New kinds of world models change this (not all are world models in the classical sense; several are latent simulators rather than explicit 3D/physics models). Based on a single image or short clip, they infer a scene you can walk inside. This is already exciting, but the structural change is how it rewrites authorship, editing, and social world building: viewers can become co-authors, routes become replayable, and style becomes a set of laws you can hand off.
→ If worlds are shareable, what’s the interface for stepping into someone else’s scene, forking it responsibly, and building it forward together?
From Views to Interactions
Until recently, the way to let you move around in a generated space was to build an explicit 3D set based on 2D images (a NeRF or splat)1. Now, new models like DeepMind’s Genie 3 or the Open-Source Matrix-Game 2.0 start from far less, just a prompt or a frame, and maintain a fast, learned representation of the scene that updates and remains consistent as you move (there is still a memory constraint).2 The result isn't perfect physics, even though this is pretty mind-blowing, too. It's real-time, procedural plausibility: parallax behaves, occlusion makes sense, light changes smoothly. Good enough to walk through and paint a wall!
For storytellers and world builders, consistency shows up on three layers: the geometry of small moves, the stability of materials and light, and the "story logic" of objects and people behaving like themselves. If this is good enough, models like Genie 3 turn everybody into directors of new realities with immediate control through exploration and interaction.
Once you’re in a scene, you can direct by moving and by adjusting the world’s rules. Instead of cutting between fixed shots, you record a spatial tour (your path and interactions) and maybe tweak how the scene behaves. Hard facts could stay pinned like universal rules. There will be something like prompt adherence and freedom parameters for generated worlds.
But what if you want to change the set while keeping certain objects? How could others take a sculpture they found in your museum, and put it into their library?
That’s where we can start thinking about a new approach to today’s world model interfaces: selective baking and constraint-aware regeneration. You can pin objects you care about, regenerate the rest around them, or bake specific elements into stable 3D so they persist across takes. Socially, this is pretty powerful: you can fork my world, keep my pinned objects or laws, but re-stage everything else. That’s how world-building starts to feel multiplayer.
Pack my world
Combining the strengths of a general purpose world model like Genie 3 with object-level recognition techniques like NeRFs and Gaussian Splatting could actually be a plausible next step towards more composable generated experiences and environments.
Here's why this combination would be pretty cool and what it would enable:
Limitations of current approaches
Currently, the core limitation of a model like Genie 3 is that it's a generative world model, not a 3D asset factory. It generates a stream of images that appear to have 3D properties and real-time physics. You can navigate the world, but the underlying geometry is implicit, not an explicit mesh or splat cloud you could simply export and use in another application or Genie world. It's more like a highly advanced, intelligent video game stream where the graphics engine is a massive AI model.
This means you can't:
Grab a specific object or character and use it in a different scene.
Import the entire generated world into a dedicated game engine for long-term development.
Edit a single object's geometry in a 3D modeling program like Blender.
Combining Genie 3 with NeRF/Splatting
This combination merges the best of both approaches: the realtime speed and creative power of Genie 3 with the portability and editability of NeRFs/Splatting. I’ve seen Bilawal experimenting with something like this.
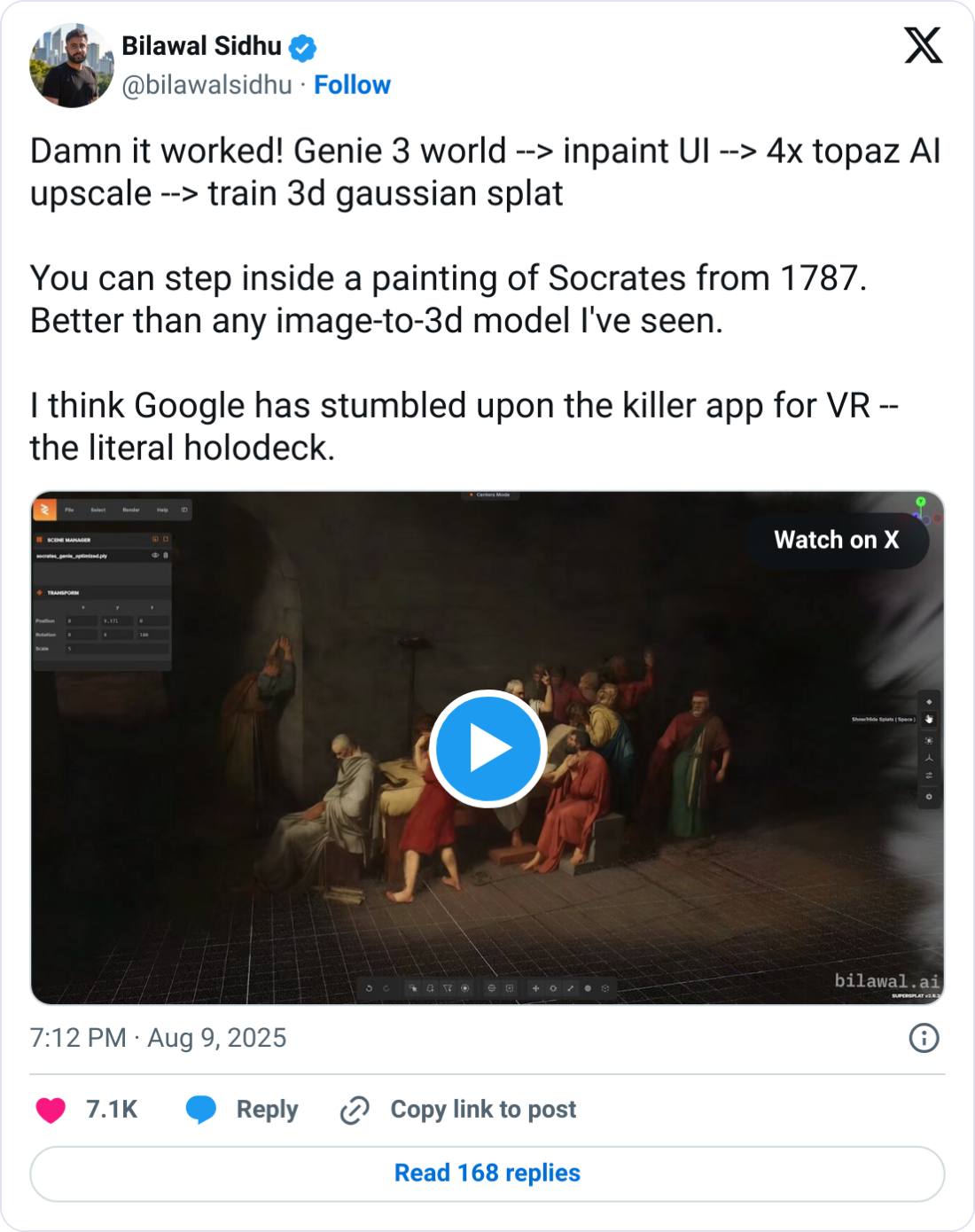
Here's how it could possibly work and what it implies for social world-building:
Real-time, High-Level World Generation: Users start by using Genie 3 to create a base environment. For example, "A factory style bakery filled with humans eating salmon tartines." Genie 3 instantly generates a navigable, interactive world with dynamic physics (great examples here). This sets the scene and gets the overall vibe right.
Object-Level “Scanning”: Now, the creator or visitor of a world captures specific, desired elements from here. A new command or a background process is initiated, instructing the system to “capture the country loaf" or "capture the big round table in the corner." The system then:
Navigates around the selected object from multiple angles.
Captures a series of 2D image frames.
Uses those frames to train a mini-NeRF or Gaussian Splatting model just for that object.
Extraction and Portability: The result is a high-fidelity 3D model of the country loaf or the table, represented as a point cloud or a radiance field. This is now a portable asset. It can be exported and:
Imported into other game engines for use in a larger, professionally developed game.
Used in a different social VR space that is not powered by Genie 3.
Shared to be remixed or edited - maybe even within Genie (once certain technical barriers will be overcome)
In essence, Genie 3 provides the brain and imagination for the world, while NeRFs and Gaussian Splatting provide the tools to capture and materialize its most compelling creations. This combination is what can take us from a fun, interactive video stream to a powerful and practical system for building, populating, and sharing immersive virtual worlds with friends and followers.
You can build generative asset libraries within worlds: Creators can build entire libraries of portable assets (objects, characters) almost on the fly by generating them in Genie 3 and then extracting them for others to use.
You get persistent worlds with dynamic and mobile elements: Social worlds need a blend of stability and dynamism. A base world could be built using traditional, high-fidelity 3D assets for consistency (e.g., the main city square). But for a specific social event, a group could use Genie 3 to instantly spawn a new, temporary area (a festival ground, a monster-infested forest). Objects from that dynamic world could then be "scanned" and brought back into the persistent world, enriching it over time.
You can create collaboratively: This process opens up 3D content creation and world building. A non-technical user could describe an object to Genie 3, a more technical user could then perform the "splatting" to extract it, and a 3D artist could then refine it in Blender. It creates a seamless pipeline from creative idea to polished, usable asset, and social appropriation, all without requiring a user to be an expert in traditional 3D modeling from the start. We’ve seen this shift happening in image and video already, now it’s coming to interactive worlds.
Worlds <> Frames
What makes generated worlds different from images or videos becomes clear when you formalize it a bit more. In traditional video, each frame belongs to exactly one timeline, one reality. But with world models things change:
Some frames are unique to one world, but others anchor multiple plausible worlds.

→ The same viewpoint (= frame), e.g. looking across a diner counter, can anchor different realities: one where it's perpetually 3am, another where morning light streams through the windows, a third where the scene plays out in noir shadows. This intersection property breaks the linear logic of traditional editing which will enable and demand new creative tools that can navigate cross-world relationships.
This formalization actually suggests two practical things about building the required interfaces for this:
Intersection frames become creative pivot points. When frames can exist in multiple worlds, those intersection points should be discoverable and highlighted in the interface. They're natural "portal" locations where users can seamlessly transition between realities or branch into new variations.
Intersection density could indicate model flexibility. While world model quality depends on many factors (temporal consistency, physics fidelity, coherence), the number of frames that can meaningfully exist across multiple worlds might serve as one useful metric for creative potential. More intersection points could enable smoother transitions between realities and richer collaborative possibilities.
A side note: You might wonder how this is different from how we experience our everyday surrounding: two individuals having the almost same view on some event at moment t but continuing their day completely differently at t+n.
Yet, in everyday perception we still share one underlying physics and tell different stories about it. Here, we can fork the environment itself with all its laws and layout. Then, we can replay, share, and merge those branches with attribution. Like the inverse of a silent disco: we all wear the same headphones but follow completely different spatial trajectories.
Interfaces for Worlds: A Social OS

The desire to be a creator, not just a consumer, comes naturally. What could be better than building a universe together with others? I remember how all my friends in school were into game-level sketching for a while: a stick figure climbs stairs, dodges spikes, jumps lava pits, collects coins, and finally reaches the flag. These sketches — part course, part map — were probably the first game-like experiences we designed.
Of course, you could draw the entire universe on your own. Instead, we passed the world around, letting others continue the next chapter of the journey we had in mind for our little main character. Once the whole world had been built, you could re-experience the odyssey by taking another color and playing through the levels again.
Demis Hassabis said something recently in a chat with Logan Kilpatrick which reminded me a lot of this ritual: The ultimate goal is letting people play in others' creations and regenerate from them. That requires a fundamentally new kind of networked framework.
Forkable worlds. Every tour through a world has fork points — maybe just one, maybe multiple. Hit a Remix button to branch the world, inherit its laws, publish your delta. Provenance ideally stays intact through a form of lineage tracking.
Credit graph & licensing. Diffs carry their parents; if monetization becomes a thing, revenue splits follow the contribution graph. Estates and artists could choose walk-in licenses: no entry, framed entry, open entry with attribution.
Co-presence. Drop a beacon and let others step into your take; hand off control at the important beats (defining the observer-to-explorer cutoff frame) → this can become real-time collaborative world-building.
Some sort of policy kits. Shareable sets of laws + style cues (like "Hopper Night”) that anyone can apply to their own seed image. Think of it as style templates we know from AI images and video now, just expanded.
Trust by design. Neural watermarks embedded in latent space, visible uncertainty indicators when you stray beyond observed content, and granular remix permissions. This will be of big importance once we have more complex and public worlds.
A lot of that will be enabled by a shared canon of assets and environments we can explore, edit, and expand together.
How It Works (Brain · Memory · Studio)
All of this culminates in a new system for creation and consumption of generated audio-visual media:
[1] The Brain (world model)
You move; the model maintains its best estimate of scene state and renders the next frame for perceptual continuity. Inference loop is fast enough to feel alive.
Obstacles today: Temporal consistency, latency, memory, true physics
[2] The Memory (live neural mapping)
An additional process can build spatial representations from multiple viewpoints. These high-confidence regions and objects can be distilled into explicit geometry ready for export into other worlds.
Obstacles today: Object separation, occlusion, geometry reconstruction
[3] The Studio (the orchestration layer)
Records your traversal as a replayable tour, enables key-framing of world parameters, manages the constraint system (pins/laws), handles branching and merging, and packages everything for distribution as interactive bundles.
Obstacles today: World state management, creative UI, replay infrastructure
While [1] and [2] involve mostly research challenges, [3] raises a design question: what should the interface feel like when you’re not just editing a scene from the outside, but actively shaping a world as you move through it? What tools, cues, and constraints will we need to direct not just images, but shared spaces in real time, and together?
If you are thinking about this, too, please let me know, I can most likely learn a lot from you!
I recommend this interview with Shlomi Fruchter and Jack Parker-Holder who were the research leads for Genie 3.
This is a fascinating.
I’ve been discussing a similar idea with friends: world models could unlock a completely new form of interacted entertainment expereiment. Imagine a TikTok where every video is not just watched but entered—something like Roblox, but with higher entertainment value, interactivity, and remixability.
In this paradigm, interaction itself becomes authorship. Your path, choices, and tweaks generate new experiences that others can view and explore, much like watching a gameplay recording on youtube but with the ability to “drop in” at any moment and continue playing with the cloud gaming technology, and start your game. With Word Models, these wouldn’t be limited to game loops—they’d become living, generative spaces.
Very interesting framing around the different layers!
Another related framing [1] I've been thinking about it is:
1. WMs can offer a non-deterministic simulation (the "brain"?) good for fast creative exploration
2. Game engines and 3D modeling tools can offer a deterministic simulation (the "memory"?) that is slower to construct, but gives fine grained control and persistence helpful for collaboration
3. 3DGS/NeRFs can help translate between the two simulations by helping transform multi-viewpoint video frames into 3D assets/scenes
If 1 is a sort of fluid, dynamic dream then 3 is a way to freeze parts of the dream and pull them into 2 for further play (with others) where you know that you won't lose it to the ephemerality of the dream.
WMs are only going to better, but perhaps the determinism (and the control/collaboration it enables) you get from actual 3D representations ends up being why they continue to be used even if we get increasingly capable and efficient WMs.
[1] Influenced by this great talk https://www.youtube.com/watch?v=hFlF33JZbA0